
 The year is 1997, a chess battle takes place between reigning world chess champion, Garry Kasparov, against IBM’s supercomputer Deep Blue. It was the first defeat of a world chess champion by a computer under tournament conditions suggesting an era of computer superiority for combinatorial problems such as chess. This event has been well documented and the subject of the documentary film “The Man vs. The Machine”.
The year is 1997, a chess battle takes place between reigning world chess champion, Garry Kasparov, against IBM’s supercomputer Deep Blue. It was the first defeat of a world chess champion by a computer under tournament conditions suggesting an era of computer superiority for combinatorial problems such as chess. This event has been well documented and the subject of the documentary film “The Man vs. The Machine”.
 The sentiment, both from Garry, and the general public was worrying that we, as humans, are being challenged by computers and that it might mark the end of chess as we know it.
The sentiment, both from Garry, and the general public was worrying that we, as humans, are being challenged by computers and that it might mark the end of chess as we know it.
Fortunately, the exact opposite has happened. Chess engines have helped us to rediscover the game and have opened up new possibilities. Chess is gaining much popularity in recent times. Much of it is contributed to a recent release of a popular mini-series “The Queen’s Gambit”, watched by 62 million households. Also, many popular streamers such as GM Hikaru Nakamura are promoting chess on modern platforms. Additionally, due to the current stay-at-home situation, chess has gained huge popularity in online chess platforms. The number of chess players on chess.com went up by 500% last year alone. Chessboard purchases went up 250% on eBay. The number of Google queries on “how to play chess” is on the record high in the last 9 years. The original novel “The Queen’s Gambit” became the new New York Times bestseller 37 years after its release.
After the Deep Blue match, chess engines, of which Stockfish is the most popular today, have evolved and allowed us to analyze games with more precision. We have used these chess engines as a learning tool. These computer programs allow anybody to have a few virtual grandmasters (highest title in chess) at home mentoring on what is a good or bad move. Previously this was time-consuming to do manually, especially for new players. Hence, what we see today is a larger number of younger grandmasters that can develop their skills by playing against chess engines. Previously, it was not as easy to get hold of human grandmasters to play against for practice. So indeed, over the years, people have realized, contradictory to the initial fears, that computers, as learning tools, can allow us to become better chess players ourselves.
 However, there was a problem. Those chess engines relied on manually crafted rules by strong players, programmers, and a brute-force approach to evaluate a position, i.e. computational heavy lifting. This is somewhat problematic in two aspects. Firstly, if humans design those rules then that system will be always limited to the limited human understanding of chess. Additionally, those rules can get complex and are hard to maintain. Secondly, chess is a highly complex game from a combinatorial point of view. According to Claude Shannon, “The father of information theory”, chess games last on average for around 40 moves. On each player move, there are around 30 possible moves on average. Considering that each move is played by both players, the white player and then the black player, giving us a number of 900 (30x30) possibilities just for a single move by both players. In total then, we end up with 10^120 (900^40) possible chess games. Considering that in the whole universe there are a total number of 10^81 atoms, we can see the problem with trying to solve chess by brute force. In short, no computer will ever be able to do so.
However, there was a problem. Those chess engines relied on manually crafted rules by strong players, programmers, and a brute-force approach to evaluate a position, i.e. computational heavy lifting. This is somewhat problematic in two aspects. Firstly, if humans design those rules then that system will be always limited to the limited human understanding of chess. Additionally, those rules can get complex and are hard to maintain. Secondly, chess is a highly complex game from a combinatorial point of view. According to Claude Shannon, “The father of information theory”, chess games last on average for around 40 moves. On each player move, there are around 30 possible moves on average. Considering that each move is played by both players, the white player and then the black player, giving us a number of 900 (30x30) possibilities just for a single move by both players. In total then, we end up with 10^120 (900^40) possible chess games. Considering that in the whole universe there are a total number of 10^81 atoms, we can see the problem with trying to solve chess by brute force. In short, no computer will ever be able to do so.
So this combinatorial explosion in chess is problematic for both humans and computers. So, how do human players sometimes evaluate 10 or move moves ahead, this should be impossible (900^10 possibilities)?! Here is the trade secret: strong players do so by evaluating only the most likely moves and the better a player is the better he/she knows what is worth evaluating. There is no point in evaluating all possibilities, but rather they rely on their experience, common sense, theory, or intuition of which moves make sense to be evaluated. They indeed call it “intuition”, but we can also call it trained pattern recognition.
Previous chess engines, such as Stockfish, Deep Blue, and others were not too smart when it came to this “intuition”, but rather relied on heavy computational capabilities to calculate many moves ahead, some of which could have been skipped in the evaluation. Those engines did employ some strategies to reduce this search space, such as alpha-beta pruning, or the mentioned custom rules on what to look for. However, this was nothing close to the “intuition” that the grandmasters have developed through playing chess. Generally, these chess engines often play moves that are non-intuitive moves compared to human moves, so it was hard to learn from those moves for us as humans as we do not possess that computational capacity to evaluate millions of positions per second. Although these chess engines were by many degrees stronger than any human player, it was lacking the style and beauty of how humans play and understand the game in an open and dynamic way, mostly due to our brain’s limitation to exhaustively compute every single position and, thus, we as humans often just “go with our guts”.
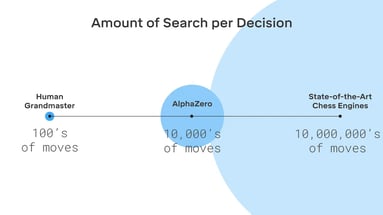 Obviously, this “intuition” aspect was lacking in previous chess engines. A British company, DeepMind, later acquired by Google, approached this problem and built a deep artificial neural network in an attempt to teach this “intuition” to computers. In only 24 hours of training, it was able to learn what a good or bad chess position is, recognize patterns thereof, and consequently beat Stockfish (at that time the strongest chess engine). So instead of hard-coding these hand-crafted rules as Stockfish has done, AlphaZero machine-learned these rules by playing against itself. Note that it took years for humans to come up with these rules programmed into Stockfish, which AlphaZero was to learn and improve within a day. At first, the moves seemed a bit random, but after some training, it started recognizing patterns of winning chess positions. What this has allowed AlphaZero is to focus its evaluation on a fewer number of possibilities, thus, reducing the search space. For instance, Stockfish evaluates tens of millions of possible moves per second. AlphaZero, on the other hand, given the trained neural network, only needs to look at a few tens of thousands of combinations and yet is able to beat Stockfish. This goes as the saying “work smarter, not harder”. Coincidently, AlphaZero shows this open and dynamic play of human grandmasters as Garry Kasparov stated himself after watching AlphaZero play. In other words, it appears that AlphaZero was able to teach itself this “intuition” by which we humans play the game.
Obviously, this “intuition” aspect was lacking in previous chess engines. A British company, DeepMind, later acquired by Google, approached this problem and built a deep artificial neural network in an attempt to teach this “intuition” to computers. In only 24 hours of training, it was able to learn what a good or bad chess position is, recognize patterns thereof, and consequently beat Stockfish (at that time the strongest chess engine). So instead of hard-coding these hand-crafted rules as Stockfish has done, AlphaZero machine-learned these rules by playing against itself. Note that it took years for humans to come up with these rules programmed into Stockfish, which AlphaZero was to learn and improve within a day. At first, the moves seemed a bit random, but after some training, it started recognizing patterns of winning chess positions. What this has allowed AlphaZero is to focus its evaluation on a fewer number of possibilities, thus, reducing the search space. For instance, Stockfish evaluates tens of millions of possible moves per second. AlphaZero, on the other hand, given the trained neural network, only needs to look at a few tens of thousands of combinations and yet is able to beat Stockfish. This goes as the saying “work smarter, not harder”. Coincidently, AlphaZero shows this open and dynamic play of human grandmasters as Garry Kasparov stated himself after watching AlphaZero play. In other words, it appears that AlphaZero was able to teach itself this “intuition” by which we humans play the game.
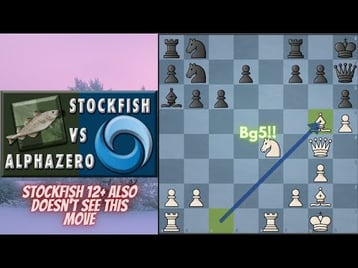
The key to surpass Stockfish and thus any human player by AlphaZero, was for it to play against itself. After each game, the outcome was measured, and the neural network adjusted using reinforcement learning. This allowed AlphaZero to evolve beyond the currently known theory and understanding of chess and yet play games that are more human-like, well maybe, super-human like. Today, chess players can observe fascinating games played by AlphaZero. This has led to a new understanding of chess, new variations in the openings, middle-games, and confirmation that our understanding of chess, in the way grandmasters have always played it, is in line with how AlphaZero plays the game.
To give an understanding of how AlphaZero plays the game, we can closely compare it to how human grandmasters play it. It generally evaluates a position on patterns. Especially on the grandmaster level, you would generally observe a chess position and have an immediate feeling of what is a favorable chess position. Although neither humans nor AlphaZero, can compute why this position is winning in the next 20 or more moves, we just know that it is winning and only need to get ourselves into that position and hope that with good play, we can convert that positional advantage into victory.
 Hence, computers as a learning tool are reminding us that one does not always need to predict the whole path ahead, but rather to have a generally good direction where to go, and we’ll get there eventually. It also reminds us that working smarter rather than harder is a better approach both for humans and computers. Also, we can see that computers can help us be better versions of ourselves.
Hence, computers as a learning tool are reminding us that one does not always need to predict the whole path ahead, but rather to have a generally good direction where to go, and we’ll get there eventually. It also reminds us that working smarter rather than harder is a better approach both for humans and computers. Also, we can see that computers can help us be better versions of ourselves.
 On another note, AlphaGo, a similar AI program also developed by Deep Mind was able to beat humans in the game of go which is even more combinatorially complex than chess (on average 250 possible moves for each player move). Although AlphaGo is better than any human, the best player of today in the game of go is a team composed of AlphaGo and human players. This is to say that humans and computers can complement each other to achieve something greater than what they would be able to on their own.
On another note, AlphaGo, a similar AI program also developed by Deep Mind was able to beat humans in the game of go which is even more combinatorially complex than chess (on average 250 possible moves for each player move). Although AlphaGo is better than any human, the best player of today in the game of go is a team composed of AlphaGo and human players. This is to say that humans and computers can complement each other to achieve something greater than what they would be able to on their own.

Previous post:
ReeTalk: Using Anxiety in Growth HackingNext post:
Sesam Self Storage Goes Digital